Score-Based / Diffusion Model[1] - Score Network
들어가며...
최근 Score-Based Generative Model through Stochastic Differential Equation 이라는 논문이 나왔습니다. CIFAR10에서 FID Score 2.20으로 stylegan2-ada를 이기고 당당하게 CIFAR10에서 SOTA를 차지했습니다. 원래 GAN에 관심이 있었던 터라 논문을 읽어보았는데, 너무 신선하고 재밌게 읽었던 것 같습니다. 아마 이 분야를 좀 더 공부하지 않을까 싶어 블로그에 글을 남길 예정입니다.
찾아보니 Score Matching이라는 개념이 2005년도부터 있었다고 합니다. (최근 대학원 수업을 들으면서 GAN논문을 다시 읽게 되었는데, 내용에 Score Matching이 있었네요.. 옛날에는 아무것도 모르는 상태로 읽어서 눈에 들어오지 않은 것 같습니다...) Yann LeCun 과 Variational AutoEncoder로 유명한 Kingma 두 분이서 Score Matching에서 regularzation 하는 논문을 쓰신 것도 발견했었는데, 이 점도 굉장히 놀라울 따름입니다.
그러다 보니 Score-Based Generative Model through Stochastic Differential Equation라는 논문을 읽기 위해 2005년도의 논문까지 읽게 되었는데, 이 분야를 공부해보고 싶은 분들을 위해 제가 공부했던, 공부할 예정인 내용들을 업로드할 예정입니다.
Score
일단, score라는 개념부터 알아보겠습니다. 그 전에, Score가 왜 등장했는지 부터 알아보겠습니다.
EBM, 즉 Energy-Based Machine에서는 우리가 알기 쉬운 f라는 함수를 통해 다음과 같이 데이터의 distribution에 접근하고자 했습니다.
$$ f_{\theta}(x) \in \mathbb{R} $$
$$ p_{\theta}(x) = \frac{e^{-f_{\theta}(x)}}{Z_{\theta}}, Z_{\theta} = \int {e^{-f_{\theta}(x)}}dx$$
로 정의하고, MLE를 통해 θ를 추정해 나가고자 합니다.
$$ \mathbb{E}_{p_{data}}[-\log p_{\theta}(x)] = \mathbb{E}_{p_{data}}[f_{\theta}(x) - \log Z_{\theta}] $$
로 θ를 추정해나갈 때, Z를 연산하는 난이도가 꽤 높습니다. Z를 계산하기 보다 없애는 것을 원하기 때문에 우리는 Score를
$$Score = \nabla_{x}\log p(x)$$
으로 정의합니다. 이렇게 되면, 연산에서 엄청난 이점을 가져갈 수 있게 되는데 Z term 은 x와 무관하기 때문에, Z term에서 x에 대한 gradient가 0이 됩니다. 따라서 우리는 데이터의 pdf에서의 gradient를 score로 정의하고자 합니다.

data distribution의 PDF와 Score를 그림으로 표현하게 되면 다음과 같은데,

vector field라 불리는 전기장의 형태처럼 만들어지게 됩니다. 결국 우리의 목적은,
$$ \nabla_x \log p_{data}(x) = \nabla_x \log p_{\theta}(x) $$
를 만족하는 파라미터 θ를 찾는 것이 Score-Based Model입니다. 그렇기 때문에 우리의 최종적인 object function은
$$ \theta^* = \arg\min_{\theta}\mathbb{E}_{\rm p(x)}{{1}\over{2}}[\vert\vert \nabla_x \log p(x) - s_{\theta}(x) \vert\vert^{2}_{2}] $$
로 정의되게 됩니다. 하지만, 우리는 p(x)를 구하기 힘듭니다. (정확히는 구할 수 없다...가 맞는 표현일 것 같습니다..) 논문에서는 implicit distribution에 대해서는 계산하기 힘들기 때문에 다른 방법을 제시하게 됩니다. 증명은 밑에 적어 놓았습니다.

여기서 간단한 Lemma를 소개해 드리고,
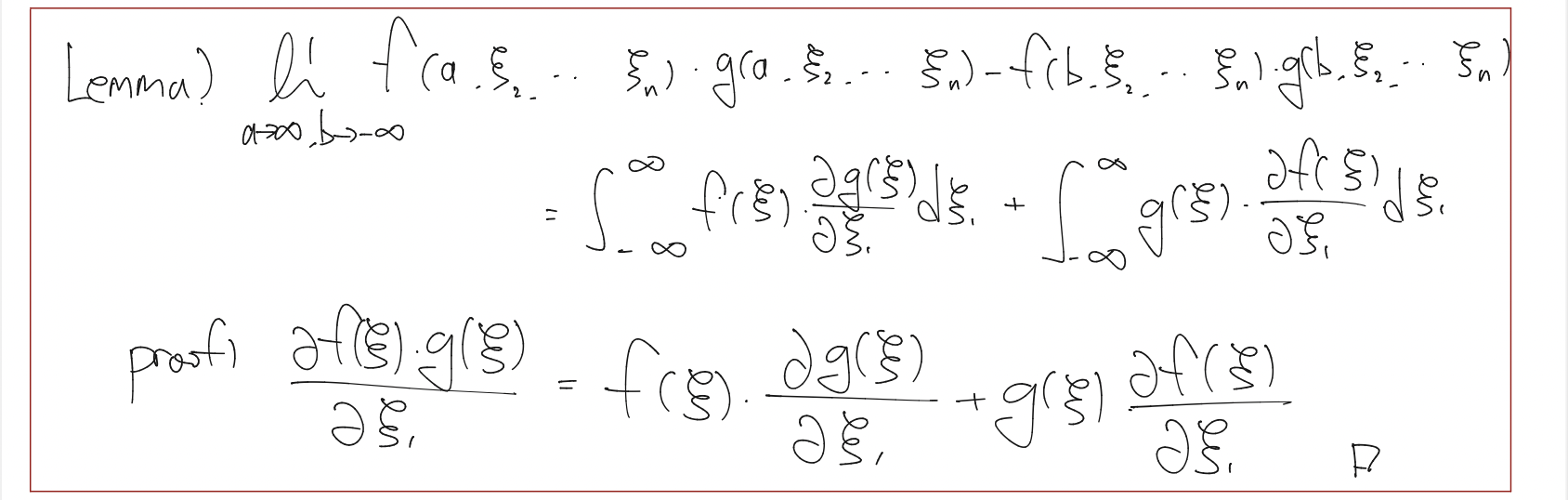
Lemma를 사용하게 된다면,

$$ \theta^* = \arg\min_{\theta}\mathbb{E}_{\rm p(x)}[{{1}\over{2}}\vert\vert s_{\theta}(x)\vert\vert_{2}^{2} + tr(\nabla_x s_{\theta}(x))]$$
로 변환이 가능합니다. implicit distribution도 계산이 가능하다는 점에서는 좋은 소식이겠지만, 계산을 하는 것이 굉장히 힘듭니다,

O(D) 만큼 backpropagation을 해야 우리가 원하는 trace를 구하게 됩니다. 예를 들면 256x256 이미지라면 총 256번의 backprogration을 해야합니다. 이 무지막지한 연산량 때문에 trace를 해결해야 합니다.
굉장히 비효율적이고, 연산과정이 복잡하기 때문에 이 trace를 해결하기 위해 여러가지 시도가 있었지만, GAN이 등장하게 되면서 Score Matching이라는 개념은 기억속에서 잊혀지게 됩니다.
그런데 2019년, Song Yang이 NCSN(Noise Conditional Score Network)이라는 논문으로 Score Network가 생성모델로써 가능성을 보여주었고, 그 후부터 Score Network에 대한 논문들이 나오게 됩니다.
그래서 다음 포스팅에서 어떤 방식으로 연산을 했는지 포스팅하도록 하겠습니다.